
온 세상이 chatGPT로 시끌벅적 하네요.
하루종일 코드 들여다 보면서 사는 사람으로서 또 안 보고 넘어갈 수 없죠.
chatGPT API 사용법을 살펴보겠습니다.
ChatGPT와 API
챗지피티 써보셨나요?
혹시 ChatGPT 써보셨나요?
검색엔진의 종말이 도래하고 있다는 말이 나올 정도로 사람의 질문과 그 의도를 잘 파악해 그럴 듯한 대답을 내놓습니다.
ai.com을 치고 들어가 로그인 하면 누구나 체험해 볼 수 있습니다.
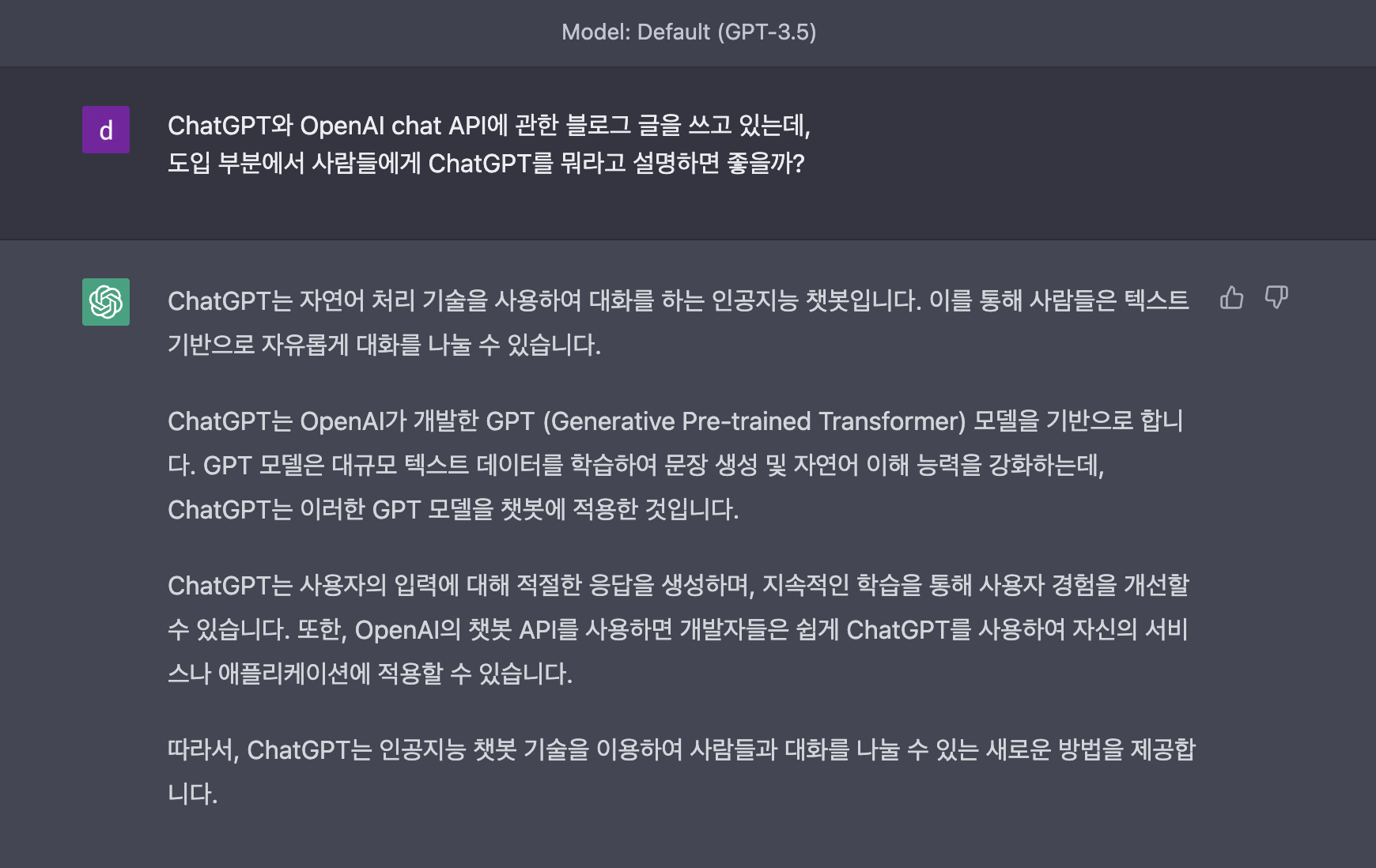
사진에서 볼 수 있듯이 ChatGPT에 대해 설명해달라고 입력하면 그에 대한 대답을 해줍니다.
말 그대로 대화가 가능한 언어 모델입니다.
이런 것도 가능합니다.
같은 말을 충청도 할머니가 아이들에게 구연동화를 하듯 다시 써달라고 하면 말투가 바뀌는 모습을 확인할 수 있습니다.

심지어는 코드도 작성합니다.
Typescript로 API 예시 코드를 적어달라고 했더니, 코드를 적어주는 것뿐만 아니라 그 아래 설명까지 자세하게 덧붙여 줍니다.

아래는 ChatGPT가 직접 작성한 ChatGPT 활용분야입니다.
ChatGPT는 대화형 인공지능으로서 다양한 분야에서 활용될 수 있습니다. 예를 들어, 대화형 챗봇, 가상 비서, 자동 번역, 자동 요약 등의 분야에서 활용될 수 있습니다. 또한, ChatGPT를 활용하여 질문 답변 시스템, 음성 인식, 자연어 이해 등을 구현할 수 있습니다.
ChatGPT의 또 다른 활용 분야로는 교육, 의료, 금융 등이 있습니다. 예를 들어, 교육 분야에서는 ChatGPT를 활용하여 학생들의 질문에 대답하거나, 자동으로 피드백을 제공할 수 있습니다. 의료 분야에서는 ChatGPT를 활용하여 의사와 환자의 상담을 대신하거나, 의학 용어를 자연어로 번역하는 등의 활용이 가능합니다. 또한, 금융 분야에서는 ChatGPT를 활용하여 고객 상담을 대신하거나, 자동으로 계좌 정보를 요약하는 등의 기능을 제공할 수 있습니다.
ChatGPT는 OpenAI API를 통해 제공되며, 간편한 API 호출을 통해 누구나 쉽게 활용할 수 있습니다. 또한, OpenAI는 강력한 보안 시스템을 갖추고 있으며, 개발자가 개인 정보 보호와 데이터 보안을 고려하지 않아도 되도록 최선을 다하고 있습니다.
이처럼 ChatGPT는 대화 생성 분야에서 뛰어난 성능을 발휘하고, 다양한 분야에서 활용 가능한 대화형 인공지능 모델입니다.
그렇다면 ChatGPT API는요?
ChatGPT API는 편의상 그렇게 부르고 있지만, 사실은 OpenAI에서 제공하는 수많은 API 중 Chat API를 의미합니다.
OpenAI에서는 Chat 말고도 다양한 언어 모델, 이미지 생성 모델, STT 모델을 제공하고 있습니다.
https://platform.openai.com/docs/introduction
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
다시 Chat API로 돌아가,
이 Chat API를 활용하면 기존에 존재하던 서비스, 혹은 새로 만드는 서비스에 ChatGPT 사이트에서처럼 사람처럼 대화하는 인공지능 모델을 손쉽게 붙일 수 있습니다.
이미 이렇게나 많은 곳들에서 Chat API를 활용하고 있습니다.

이런 밈이 나올 정도니까요.

심지어는 이런 것도 가능합니다.
아래는 Chat API로 유튜브 영상 댓글에 답글을 자동으로 남겨주는 봇을 만든 예시입니다.
https://www.youtube.com/watch?v=bQ8anzYwaKY
간단하게 구현해보기
얘기가 더 길어지기 전에 실제로 API 연결을 해봐야겠죠.
API 연결은 Docs에 꽤나 잘 설명이 되어 있습니다.
API 연결 테스트를 더 재밌게 해보기 위해 저는 잘 만들어진 오픈소스 사이트 소스코드를 하나 가져왔습니다.
ChatGPT와 비슷한 UI입니다.
https://github.com/mckaywrigley/chatbot-ui
GitHub - mckaywrigley/chatbot-ui: An open source ChatGPT UI.
An open source ChatGPT UI. Contribute to mckaywrigley/chatbot-ui development by creating an account on GitHub.
github.com
만약 API를 붙여보고 싶은 사이트가 있다면 본인의 사이트로 진행해도 좋습니다.
API Key 받기
우선 OpenAI에서 API Key를 발급받아야 하는데요,
아래 사이트에 들어가서 발급받을 수 있습니다.
https://platform.openai.com/account/api-keys
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
발급 받은 키는 추후에 다시 확인할 수 없으니 잘 적어두어야 합니다.
Docs에서 템플릿 코드 가져오기
일단 아까 가져온 API Key로 Authentication을 해주어야 합니다.
Docs에 설명이 잘 되어 있습니다.
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com

우린 Typescript로 작성을 하고 있으니 가장 아래에 위치한 Node.js 예시대로 써주면 됩니다.
const configuration = new Configuration({
organization: 'org-hVb9jLGgEG18b8M3S4DskHc9',
apiKey: 'sk-...', // 위에서 받아온 api key
});
const openai = new OpenAIApi(configuration);
Authentication이 되었으면, 실제로 api call을 해봐야겠죠.
이 코드도 Docs에 잘 설명이 되어 있습니다. 그대로 가져와 볼게요.
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: '여기에 사용자가 입력한 텍스트를 넣어줍니다.' }],
});
model과 role 옵션에는 어떤 것이 있는지는 아래에서 살펴볼 예정이니 지금은 일단 넘어가도 되고,
content에만 사용자가 <Input />을 통해 입력한 문장을 넣어주면 됩니다.
content에 담긴 문장을 바탕으로 모델이 답변을 생성하게 됩니다.
예시로, 우리가 익숙한 ChatGPT UI에서는 이 부분에 해당합니다.

이렇게 되면 reponse에 ChatGPT가 생성한 답변이 담기며, API 연결이 끝납니다. 간단하죠?
혹시 위에서 링크 달아드린 chatbot-ui 프로젝트로 API 테스트를 진행하고 계신 분이라면 아래 접힌 글에 부연 설명이 있습니다.
위에 보여드린 chatbot-ui 프로젝트로 따라오고 계신 분들을 위해 추가로 설명을 덧붙입니다.
(추가 예정)
Response의 구조
안녕 너는 누구니? 라고 입력해 response를 받아봤습니다.

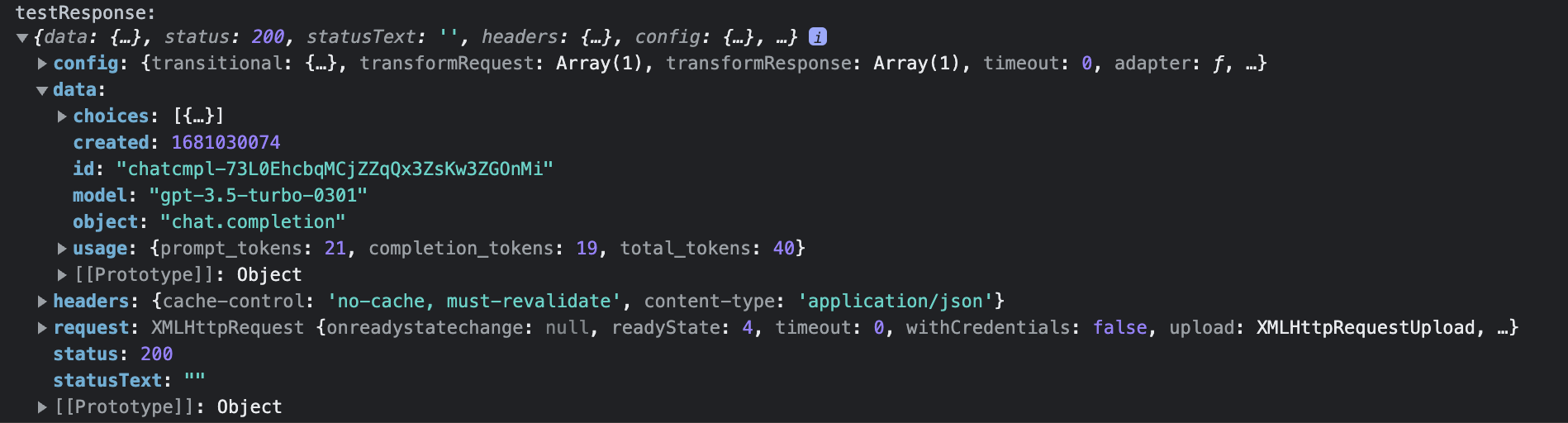
respons에 담겨 온 data를 보면 여러 정보가 있는데,
choices에 언어 모델의 답변들이 담겨 있고,
id, model, object는 각각 api call의 property를 담고 있습니다.
그리고 usage에는 해당 call이 얼마만큼의 token을 소모했는지에 대한 정보가 담겨 있는데, 이 token은 API 요금 정산에 사용됩니다. 밑에서 좀 더 자세하게 알아보겠습니다.
그런데 자세히 보면 답변이라고 하는 choices가 배열로 이루어져 있는 걸 볼 수 있습니다.

API 호출을 할 때 n 파라미터에 받을 답변의 개수를 정할 수 있는데요,
디폴트로는 1개가 제공되고, n에 따로 값을 주면 여러 개를 받아볼 수도 있는 방식입니다.
우리는 답변 개수를 따로 지정하지 않았기 때문에,
choices 배열에는 답변이 1개 담겨 왔고,
message 안에 content에 그 답변이 적혀있는 걸 확인할 수 있습니다.
따라서,
response.data.choices[0].message?.content로 접근하면 답변을 화면에 띄워줄 수 있겠네요.
하나하나 뜯어보기
간단히 API 호출을 해보는 것은 성공했으니, 이제 어떤 호출에 옵션들이 있는지 하나하나 뜯어 보려 합니다.
그걸 알아보기 좋은 사이트가 있는데요,
OpenAI가 제공하는 Playground입니다.
https://platform.openai.com/playground?mode=chat
플레이그라운드에서 제공하는 옵션들은 그대로 API의 파라미터로 제공하고 있으므로,
플레이그라운드에서 감을 잡은 뒤에 코드로 옮겨보도록 하겠습니다.
Role
위에서 템플릿 코드를 따라 적으며 role: 'user'로 되어 있는 부분은 추후에 설명할 테니 넘어가자고 했었는데요,
이 role에는 세 가지가 있습니다. (Docs 참고)
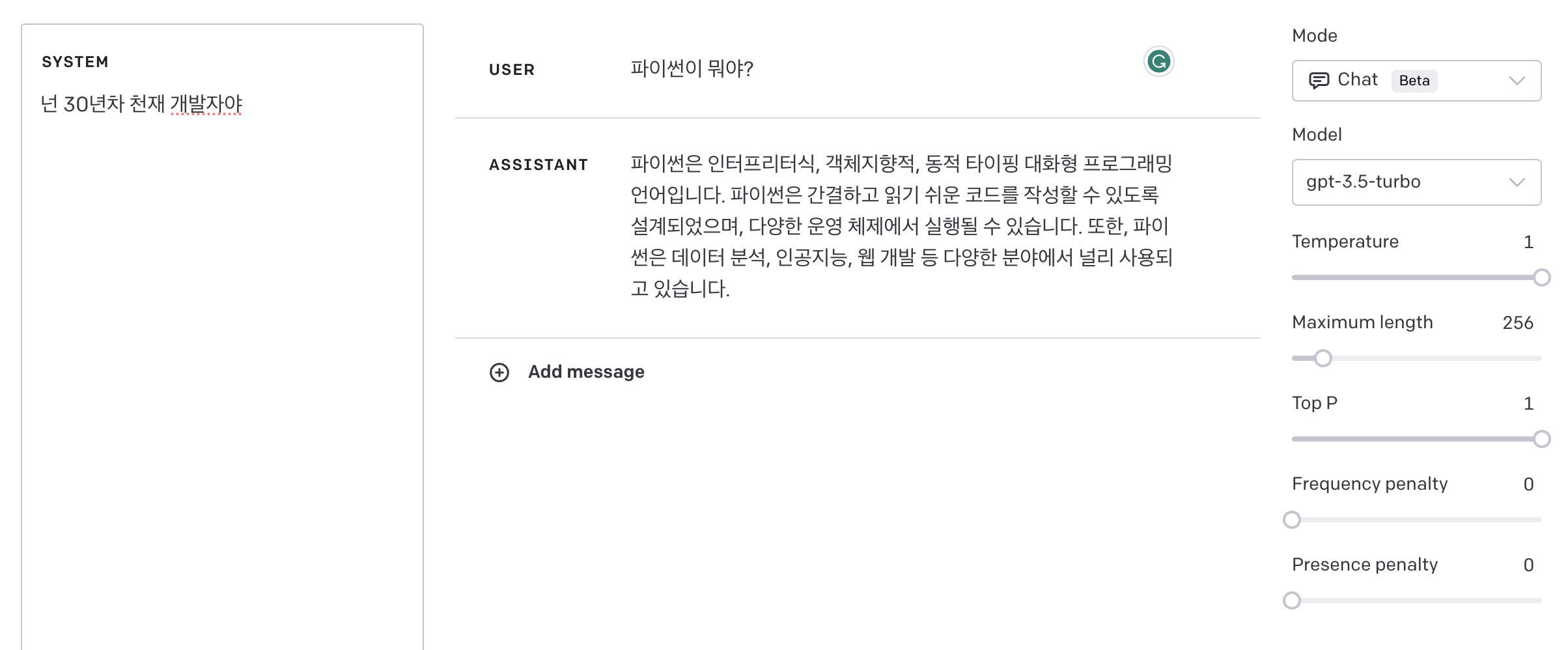
- system: 어떤 행동을 하는 시스템인지. 쉽게 말해 어떤 거에 빙의할 것인지.
- 예) "넌 천재 30년차 개발자야"
- assistant: 개발자가 원하는 동작의 예시 제공. 추가 정보나 답변 가이드 제공. 이전 답변을 기억하는 용도로 사용.
- user: 최종 사용자. 답변 가이드로 사용 가능.
그래서 system을 설정해준 후 user와 assistant를 번갈아 넣어주면 됩니다.
아래는 Docs에서 제공하는 예시입니다.
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)이 모델은 도움이 되는 어시스턴트에 빙의할 것이고,
LA다저스가 2020년에 월드 시리즈 우승을 했다는 사실을 기억하고 답변할 것이며,
마지막 '경기는 어디서 진행됐어?'라는 질문에 어떤 경기인지 생략이 되어 있어도 2020년 LA 다저스의 월드 시리즈 경기라는 걸 전제해 대답할 것입니다.
System에 충청도 할머니에 빙의하라고 적었고, User에 '할머니 식사하셨어요?'를 넣었더니,
AI 모델이 Assistant role로 답변을 생성해준 모습을 볼 수 있습니다. (그나저나 ChatGPT는 충청도 사투리를 모르는 것 같네요..)
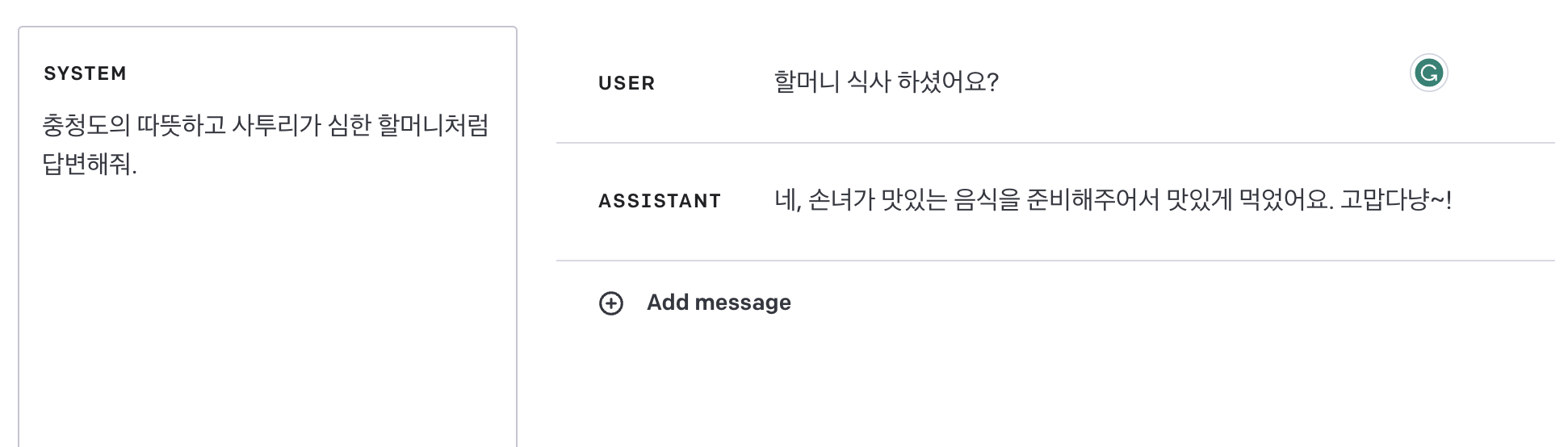
바로 이어서 '뭘 준비했길래요?' 라고 질문하니,
그 전 Assistant를 통해 '뭘'의 맥락을 이해하고 '음식'이라고 유추해 바로 어떤 음식을 먹었는지 답변을 주는 모습을 볼 수 있습니다.

N
이 API는 기본적으로 1개의 답변만을 제공합니다.
하지만, 서비스에 따라 여러 개의 답변을 제공받아야 하는 경우도 있겠죠?
예를 들면, 단체 채팅방을 생각해볼 수 있습니다.
내가 질문을 하나 보내면 여러 친구들이 우르르 답변을 해줘야 하는 경우가 있을 수 있겠네요.
또, 사용자에게 여러 답변을 보여주고 가장 마음에 드는 답변을 취사선택할 수 있도록 하게 하는 경우도 있을 수 있습니다.
이런 경우를 위해 답변의 개수를 n 파라미터를 사용해 원하는 개수로 조정할 수 있습니다.
const testResponse = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: 'Tell me about your hobbies and interests' },],
n: 4 // 4개의 답변을 생성해줘
});
이렇게 생성된 답변들은 response의 choices 배열에 차곡차곡 담기게 됩니다.
Temperature과 Top p
Temperature와 Top-p는 생성된 텍스트의 다양성과 신뢰도를 조절하는 데 사용되는 설정값입니다.
GPT3에서는 이 둘을 적극적으로 활용하고 있지만, 언어 모델에서의 더 많은 전략은 아래 블로그에 잘 설명되어 있습니다.
https://littlefoxdiary.tistory.com/46
Transformer로 텍스트를 생성하는 다섯 가지 전략
Hugging face에서 정리한 자연어 생성 디코딩 전략 포스팅을 번역 & 정리한 포스트입니다 ❤️ Source - hugging face ❤️ 더 좋은 디코딩 전략으로 자연어 생성 모델의 성능 높이기 원본 포스팅: https://hu
littlefoxdiary.tistory.com
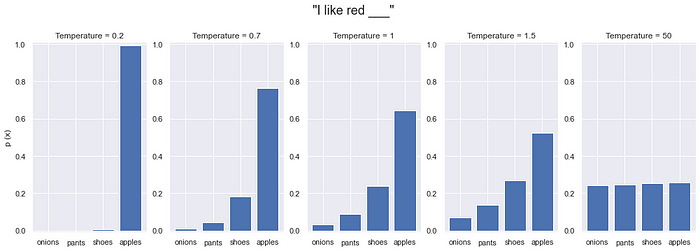
[Temperature]
엔트로피. 모델이 다음에 생성할 단어를 선택할 때, 그 선택이 얼마나 다양할지를 결정합니다.
쉽게 말해, 얼마나 까다롭게 단어를 고를 것이냐를 조절합니다.
- 높은 Temperature 값을 사용하면 조금 더 예상할 수 없는 다양한 텍스트가 생성되고, (덜 까다로움)
- 낮은 Temperature 값을 사용하면 텍스트가 좀 더 일정하고 일관적인 편이 됩니다. (까다로움)
- 가장 확률이 높은 단어 선택 -> 거의 항상 같은 답변
[Top p]
모델이 다음에 선택할 후보 단어를 제한하는 역할을 합니다.
- Top-p 값이 높을수록 후보 단어의 수가 많아져 다양한 텍스트가 생성됩니다. (1.0일 때 모든 단어가 후보가 됨)
- Top-p 값이 낮을수록 후보 단어의 수가 줄어들어 선택된 텍스트의 신뢰도가 높아집니다. (0.5일 땐 가장 많이 쓰이는 상위 50% 단어만 후보가 됨)
예를 들어, 다음에 선택될 수 있는 단어 20개가 이렇게 있다고 가정해보겠습니다.
"the": 0.25
"a": 0.15
"cat": 0.10
"sat": 0.05
"on": 0.05
"mat": 0.03
"it": 0.02
"was": 0.02
"and": 0.02
"ate": 0.02
"the": 0.01
"hat": 0.01
"with": 0.01
"rat": 0.01
"in": 0.01
"that": 0.01
"pat": 0.01
"fat": 0.01
"bat": 0.01
"chat": 0.01Top-p가 0.05일 때는 선택할 수 있는 단어가 상위 5%, 즉, the 밖에 선택하지 못합니다.
반면 Top-p가 0.5이면 상위 50%, 즉 (“the”, “a”, “cat”, “sat”, “on”, “mat”, “it”, “was”, “and”, “ate”) 단어 중 랜덤으로 선택합니다.
한 마디로,
Temperature는 모델의 선택 다양성을 제어하고,
Top-p는 후보 단어들을 제한하여 생성된 텍스트의 신뢰도를 조절하는 데 사용됩니다.
아래는 예시입니다.

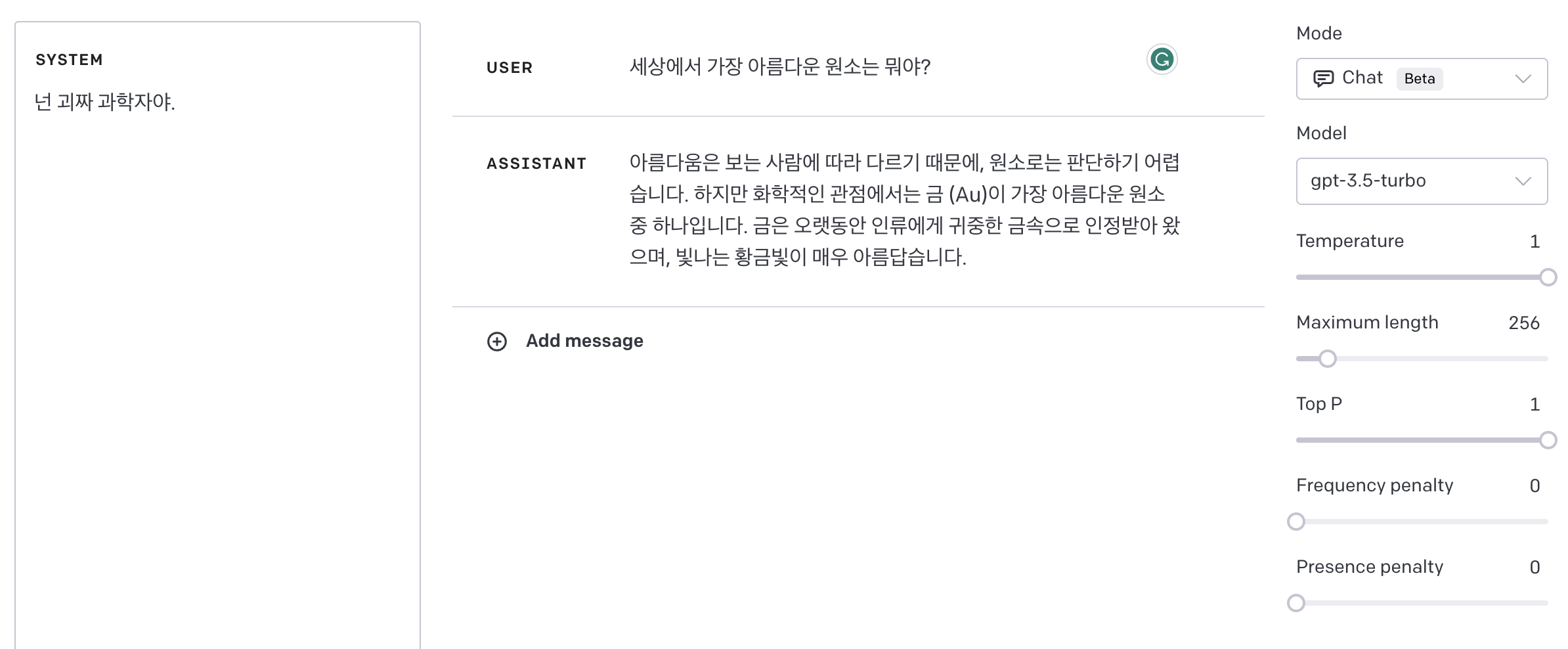
객관적인 질문을 하니 답변이 비슷한 것 같아서, 조금 더 주관적인 질문을 해봤습니다.
어째 반대로 된 것 같지만, 어쨌든 결과는 아래와 같았습니다.

Presence/Frequency Penalty와 Logit Bias
생성되는 텍스트의 다양성을 조정할 수 있는 세 가지 파라미터가 있습니다.
[presence panalty]
presence_penalty는 이전에 생성된 텍스트에 나타난 토큰에 대한 확률 페널티를 적용하는 데 사용되는 매개 변수입니다.
한 마디로, 주제의 다양성에 관여할 수 있습니다.
presence_penalty 값을 높이면, 이전에 생성된 텍스트에 나타난 토큰이 다시 생성되는 것을 방지할 수 있습니다.
이렇게 하면 모델이 새로운 단어와 구문을 생성하는 데 더 집중하게 되어, 대화가 더 다양해질 수 있습니다.
반대로, presence_penalty 값을 낮추면, 이전에 생성된 텍스트에 나타난 토큰이 다시 생성될 가능성이 높아집니다.
이 경우, 모델은 이전 대화 내용과 관련된 단어와 구문을 계속해서 생성할 가능성이 높아집니다.
예를 들어, 대화에서 이전에 언급한 것이 "사과"인 경우, presence_penalty 값을 높여서 모델이 "사과"와 관련된 단어를 자주 반복하지 않도록 강제할 수 있습니다.
하지만 '사과' 단어 자체가 이전에 몇 번 등장했었는지에 대해서는 관심을 갖지 않습니다. (이 부분은 frequency penalty가 관여합니다)
presence_penalty를 잘 조절하면 모델이 대화에서 새로운 주제를 탐색할 가능성이 더 높아지므로, 대화가 더 흥미롭고 다양해질 수 있습니다.
presence_penalty와 함께 frequency_penalty를 사용하면, 생성된 텍스트의 다양성을 더욱 향상시킬 수 있습니다.
frequency_penalty는 이전에 생성된 텍스트와 중복되는 토큰에 대한 확률 페널티를 적용하는 것입니다. 이 두 가지를 함께 사용하여 모델이 다양한 대화를 생성하도록 할 수 있습니다.
[frequency penalty]
frequency_penalty는 생성된 텍스트에서 이전에 생성된 텍스트와 중복되는 토큰에 대한 확률 페널티를 적용하는 데 사용되는 파라미터입니다.
다시 말해, 선택하는 단어 자체의 다양성에 관여할 수 있습니다.
- 높을수록, 이전에 생성된 텍스트와 중복되는 토큰이 더 높은 확률로 페널티를 받게 되므로, 모델이 이전에 생성된 텍스트를 반복하지 않도록 유도할 수 있습니다.
- 0.0은 페널티를 적용하지 않는 것을 의미합니다.
- 낮을수록, 중복 토큰이 더 많이 생성될 가능성이 있습니다. 같은 말을 반복하게 할 수 있습니다.
이러한 특성 때문에, frequency_penalty는 주로 생성된 대화의 일부가 이전 대화와 비슷하게 보이는 것을 방지하는 데 사용됩니다.
이전 대화에서 자주 나타나는 단어 또는 구를 감소시켜서 반복되는 대화를 줄일 수 있습니다.
예를 들어, 이전 대화에서 "안녕하세요"와 "어떻게 지내세요"라는 문장이 자주 나타나면,
frequency_penalty 값을 증가시켜서 이전 대화에서 자주 나타나는 문장이 다시 생성되는 것을 방지할 수 있습니다.
또한, frequency_penalty를 적절하게 조정하면 모델이 보다 다양한 대화를 생성할 수 있으며, 대화의 흐름을 자연스럽게 유지할 수 있습니다. 이 때, frequency_penalty는 이전에 생성된 텍스트와 관련된 내용을 계속 생성하도록 모델을 유도하는 것이 아니라, 중복을 피하면서 다양한 텍스트를 생성하게끔 돕습니다.
[logit bias]
logit_bias는 모델이 출력하는 확률을 조정하여, 특정한 단어나 구문이 더 자주 나오도록 유도하는 기능입니다. 예를 들어, chatbot을 구현할 때, 특정한 단어나 구문을 우선적으로 사용하도록 logit_bias 값을 설정하여, chatbot이 더욱 적절한 대답을 하도록 유도할 수 있습니다.
logit_bias는 JSON 형식으로, tokenizer에서 사용하는 각 단어나 구문에 대한 ID와 그에 해당하는 bias 값을 지정하여 사용합니다. 예를 들어, "hello" 단어의 ID가 123이라면, 다음과 같이 logit_bias 값을 설정할 수 있습니다.
logit_bias = {"123": 2.0}
위와 같이 설정하면, "hello" 단어가 더 자주 사용되도록 모델이 출력하는 확률을 높여줍니다.
bias 값이 높을수록 해당 단어가 선택될 확률이 높아집니다.
logit_bias는 특정 단어나 구문에 대한 선택 확률을 조정하는 것이기 때문에, presence_penalty나 frequency_penalty와 함께 사용될 수도 있습니다. 예를 들어, logit_bias로 특정한 단어나 구문의 선택 확률을 높이고, frequency_penalty로 새로운 주제에 대한 대답을 유도하면서 반복되는 답변을 방지할 수 있습니다.
Max Tokens
max_tokens는 생성된 챗봇 응답에서 최대 토큰 수를 지정하는 매개변수입니다. 이 매개변수를 사용하면 챗봇이 생성하는 응답의 길이를 제한할 수 있습니다. 이를 통해 응답이 너무 길어지는 것을 방지하거나, 일정한 길이의 응답을 보장할 수 있습니다.
예를 들어, 챗봇이 사용자의 질문에 대해 최대 50개의 토큰으로 응답하도록 설정하면, 응답은 50개의 토큰을 초과하지 않을 것입니다.
이를 통해 챗봇이 긴 응답을 생성하는 것을 방지하고, 응답의 일관성을 유지할 수 있습니다.
단 한 줄의 답변을 바란다면 이 파라미터를 적용해 볼 수 있겠네요.
하지만 이 매개변수를 너무 작게 설정하면, 챗봇이 충분한 응답을 생성하지 못할 수 있으므로, 적절한 값을 선택해야 합니다.
stop
stop은 API에 전달되는 문자열 또는 문자열 배열로, 모델이 더 이상 토큰을 생성하지 않도록 지시하는 역할을 합니다.
예를 들어, 다음과 같은 입력 메시지가 있다고 가정해 봅시다.
{
role: 'user',
content: 'Tell me about your hobbies and interests'
}
그리고 우리가 좋아하는 것들이 이미 다음과 같이 이미 이야기가 나온 상황이라면,
{
role: 'assistant',
content: 'I enjoy hiking, reading, and playing video games'
}
모델이 이미 나온 취미나 관심사를 다시 말하지 않도록 하기 위해서 stop 매개 변수를 사용하여 이렇게 제한할 수 있습니다.
const testResponse = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: 'Tell me about your hobbies and interests' },],
stop: ['hiking', 'reading', 'video games'], // 이 단어들을 빼고 답해줘
});
이 경우, 모델이 이전 대화에서 언급한 취미와 관심사를 반복하지 않도록 막을 수 있습니다.
User
만약 이 API를 활용해 서비스를 만든다면, 악의적인 사용자를 거를 준비가 되어 있어야 할 겁니다. 어딜 가나 악성 유저는 있기 때문에...
이 user에 우리 서비스에서 관리하고 있는 uid나 다른 비슷한 고유한 인디케이터를 넣어주면,
각 사용자를 식별하고 사용량을 추적하며, 남용이나 악의적인 요청을 감지하고 차단하는 데 사용할 수 있습니다.
const testResponse = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: 'Tell me about your hobbies and interests' },],
user: 'aeafEAeiaVe93nfa' // 고유 uid
});
Token
Chat API는 텍스트를 토큰 단위로 끊어 처리합니다. (사실 이건 이 모델 뿐만 아니라 NLP 전반에 적용됩니다.)
Token은 자연어를 처리할 때 가장 작은 단위의 단어나 기호를 의미하는 용어입니다.
보통은 공백 문자를 기준으로 단어를 분리하지만, 이러한 분리 기준이 항상 적절한 것은 아닙니다.
예를 들어, "New York"이라는 단어를 하나의 토큰으로 인식하는 것이 일반적입니다.
언어 모델은 입력으로 사용되는 문장을 토큰 단위로 쪼개어, 모델이 처리할 수 있는 형태로 만드는 과정을 거칩니다.
모델마다 토큰을 어떻게 분리하는지에는 차이가 있지만,
Chat API를 통해 들어가고 나오는 토큰은 여기서 확인해 볼 수 있습니다.

Mode
우리는 Chat API만 보고 있지만, 사실 다양한 모드를 선택할 수 있습니다.

오늘 주제는 Chat이라 하나하나 깊게 다루지는 않겠지만 이런 것도 있구나를 알아두는 정도로도 의미있을 것 같습니다.
[Complete]
문장을 완성합니다.
아래는 주석만 보고 코드를 완성하는 예시와,
번역하라는 명령 문장을 주고 '1.' 까지만 적었을 때 그 뒤로 문장을 만드는 예시입니다.


[Chat]
우리가 지금까지 써오던 Chat입니다.

[Insert]
문장 중간에 [Insert] 태그를 집어넣으면 거기에 맥락에 맞는 문장을 생성해줍니다.

[Edit]
마지막으로, 글과 Instruction을 입력하면 글을 Instruction대로 다시 써주는 모드입니다.
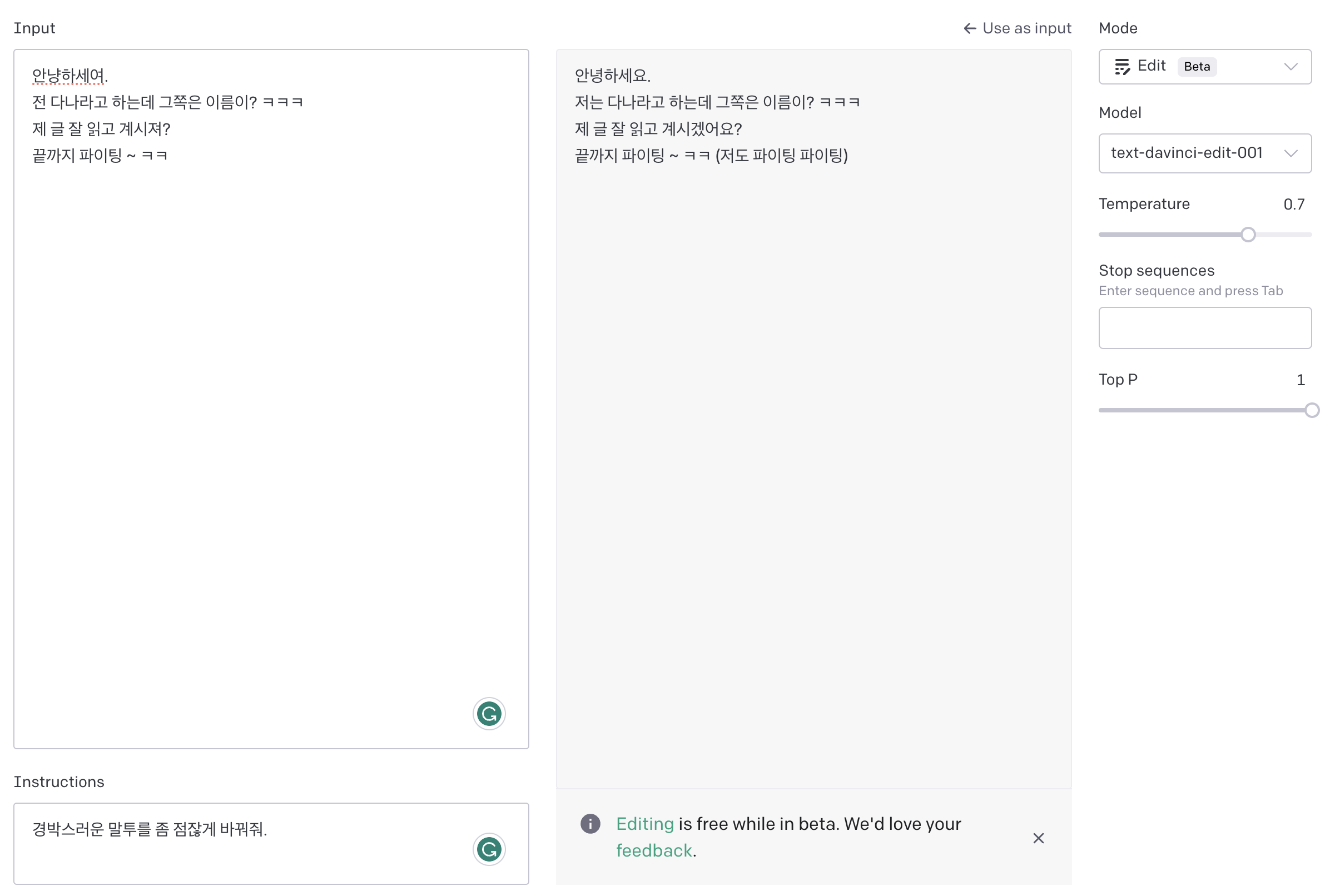
이렇게 간단히 API 연결을 해보고, 하나하나 뜯어보았는데요,
다음 글에서는 어떻게 하면 더 견고한 구조를 만들고 세밀하게 옵션을 조정해 재미있는 서비스를 만들 수 있을지에 대해 적어보겠습니다.
'개발 잡기술' 카테고리의 다른 글
| Metabase(메타베이스)를 활용해 데이터 시각화하기 (2) | 2024.01.07 |
|---|---|
| 사이드 프로젝트에 미친 사람이 서비스 20개 만들면서 느낀 것들 (15) | 2023.12.10 |
| Wix에서 카카오 API 사용하기 (도메인 에러 해결) (4) | 2023.05.17 |
| [Typescript] OpenAI의 ChatGPT API로 나만의 챗봇 만들어보기 Part. 2 (1) | 2023.04.11 |
| 개발 협업에서 Git & GitKraken 사용하기 (2) | 2023.04.08 |